Assumptions and considerations
The document is built based on the assumption that the following entities to be migrated in an automated way:
Packages
Main fields
Summary
Description
Start Date
Release Date
Versions in Package
Status (Column)
Milestones
Tags
Comments
Versions
Main fields
Summary
Description
Start Date
Release Date
Status (Column)
Tags
Milestones
Comments
All other entities are to be manually migrated.
Virtual versions are not covered by this guide.
We assume that before this guide is started, all projects, fix visions, and issues have already migrated from the Data Center (DC) to the Cloud instance
Version and package creation/update dates and original history items will be lost.
Comment author and creation date will be lost
In the guide, we will use new terminology where Releases have been renamed to Packages
All manual migration steps should be done before migrating the data via API
Step 1. Manual entities migration
Some entities are better migrated manually for the following reasons:
The number of such entities is typically low.
The manual migration process is straightforward and less prone to errors.
Writing a script for these cases may be more complex than performing the migration manually.
Boards
Boards can be manually recreated in the new instance. When doing so, ensure you replicate the permissions assigned to the original board.
Steps & Transitions
Workflow steps, transitions, and restrictions should also be manually copied between boards.
If there are numerous boards or steps, an automated guide can be provided.
To access an API migration guide, contact support@releasemanagement.app
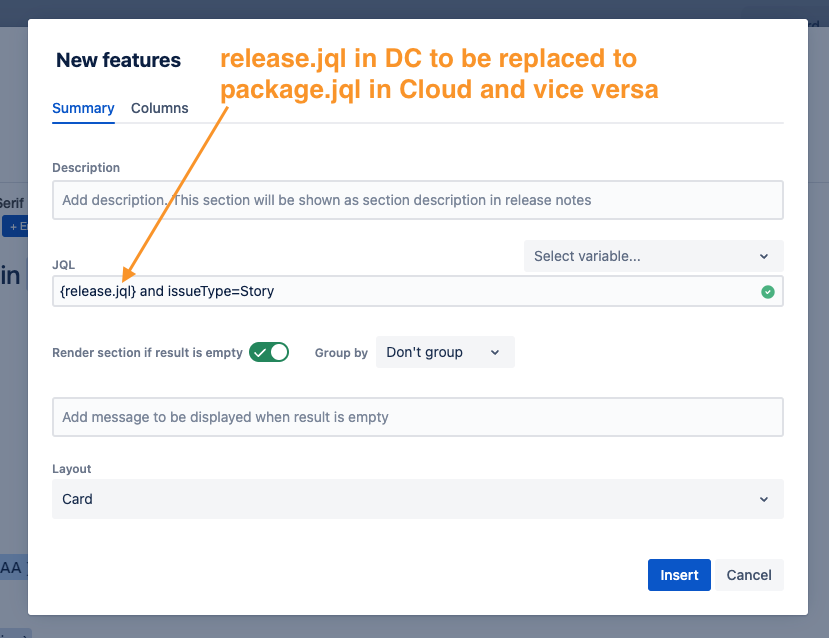
Release Notes
Release notes should be manually copied, with one key adjustment:
In Data Center packages,
{release.jql}is used for JQL tables, whereas{package.jql}is used in the Cloud.Update each JQL table after migration to match this convention.
Gadgets
Gadgets require manual migration.
Follow the detailed guide available here: Migration of Gadgets.
Special permissions
Recreate special permissions manually on both global and project levels, such as:
Release Management without project admin permissions.
Global Properties
Global properties must be created in the Cloud environment before migration.
Step 2. Main migration flow
The overall flow will look like the one below. The flow is explained on a board basis, so it has to be repeated for each board to be migrated.
Data Extraction from the DC instance
Get board data
Prepare lookup tables to map DC and Cloud entity IDs
Version Processing
Extract version details
Extract Milestones
Extract Tags
Extract Comments
Package Processing
Extract version details
Extract Milestones
Extract Tags
Extract Comments
Data writing to Cloud Instance
Write package data
Create packages with basic data
Apply package to version mapping
Create Milestones
Create Tags
Create Comments
Write versions data
Update versions with Tags
Update versions with Milestones
Update versions with Comments
Step 3. Prepare global pre-requisites
Authentication
Before starting the work, make sure that the authentication mechanisms are up and running for DC and Cloud instances.
Obtain DC authentication token: https://releasemanagement.atlassian.net/wiki/spaces/RM4J/pages/1081347/Swagger+Rest+API+Integrations#How-I-can-get-a-Token-to-access-API%3F
Leard on how to obtain a Cloud authentication token.
NOTE: toke lifetime is 15 mins so this procedure should be repeated before each call to Cloud RM API or within 15 mins timeframe with the same token
Entity mapping
The IDs for DC and Cloud are different, so in order to match the entities, we need to create lookup tables that can help us calculate DC and Cloud entities.
The following lookup tables are to be created:
Proejct ID DC -> Project ID Cloud
Version ID DC -> Version ID on Cloud
Board ID DC -> Board ID Cloud
The boards on the Cloud instance should be manually created with the same config (project, permissions, statuses, transitions, etc) before the migration is started.
For each board:
The same columns should be manually created on the Cloud instance before starting this step
Package column ID mapping: DC package ID -> Cloud Package ID
Version column ID mapping: DC version ID -> Cloud version ID
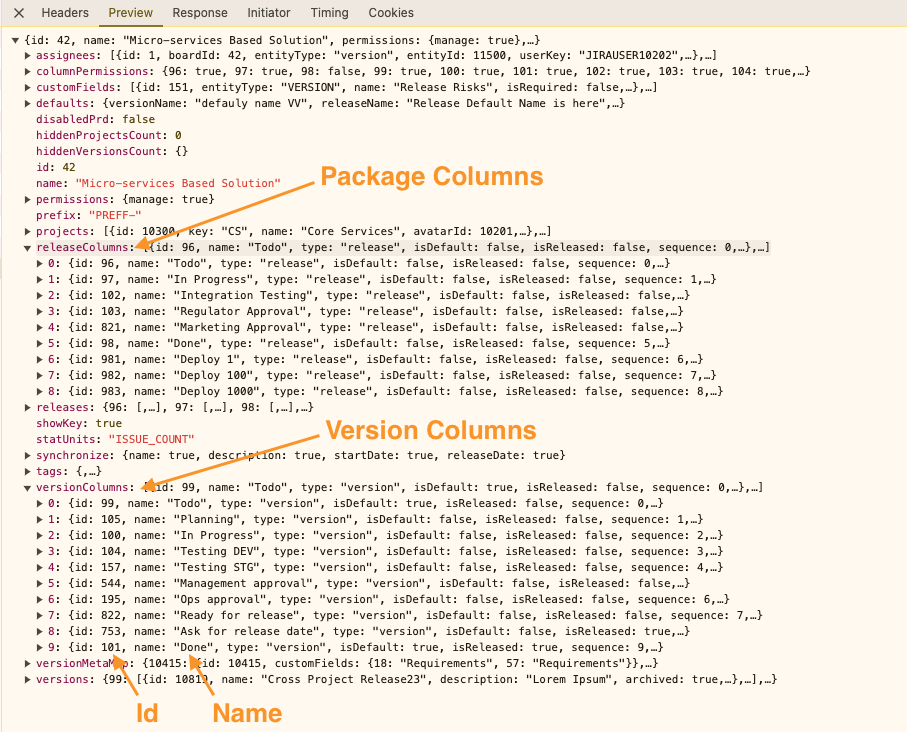
DC Column could be obtained by:
GET "https://<your_jira_url>/rest/release-management/1.0/board/<board_id>"
Headers: "content-type: application/json"
In the response please find a collection with version and package column ids and their mapping to name, Name will be used to map DC and cloud columns:
Cloud Get Columns:
GET https://rmcloud-prd.releasemanagement.app/api/1/board/<board_ID>
In the response:

All these lookup tables will be used in the further steps.
Step 4. Data extraction
Before start
Pick the board and get this board ID - <board_id>
Data Extraction Guides
Get the whole board data:
GET "https://<your_jira_url>/rest/release-management/1.0/board/<board_id>"
Headers: "content-type: application/json"
Iterate all packages
The packages collection is grouped by Column ID so, let’s take column by column and iterate all packages inside each column:
Iterate all columns:
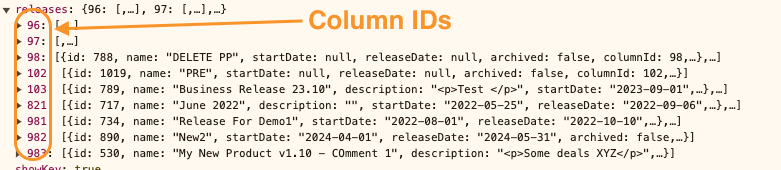
In each column, iterate packages, and from each package save:
Release ID
Archived Flag
Dates
Name
Description (not shown in the screenshot, as it is empty, but it will be presented in the response if the value is available)
Version mapping. Ids would be enough, other version data will be later
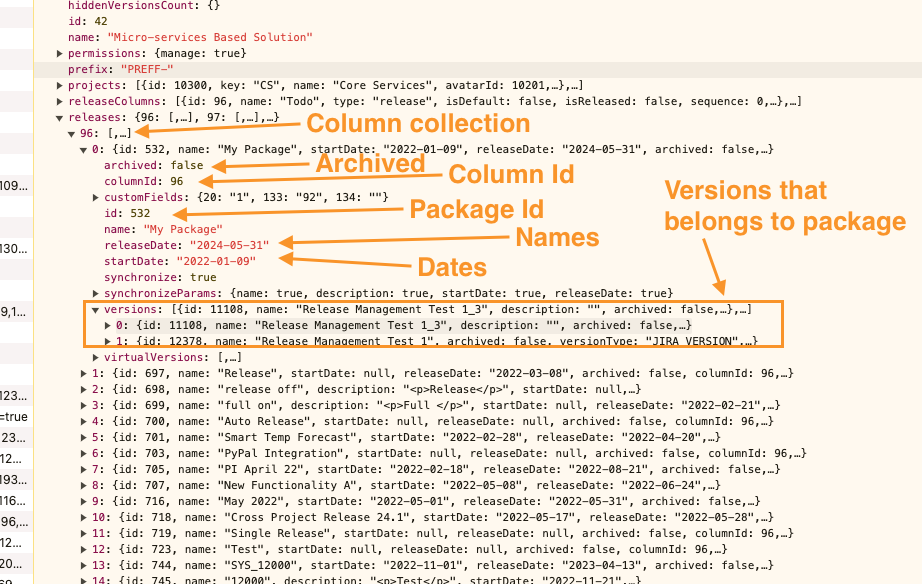
If needed, in the same way, virtual versions could be integrated and stored (this case is not covered in this guide)
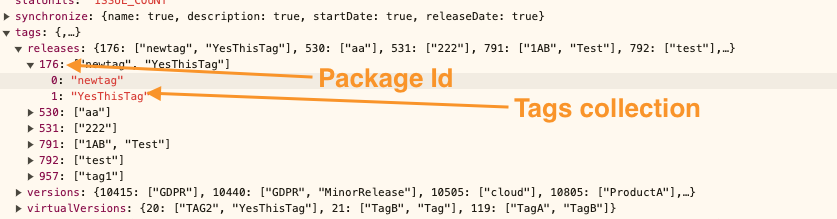
As a result, we will get all Packages but without, tags, and comments
Enrich Packages with Tags from the same response extract tags from Collection: Tags-> Releases
In order to get comments, for each Package ID, execute the request:
GET https://<your_jira_url>/rest/release-management/1.0/release/comment/<release_id>/comments
Get the response and store comment values for each package. All other fields are not needed

In order to get Milestones, for each Package ID, execute the request:
GET https://<your_jira_url>/rest/release-management/1.0/release/<package_id>/milestone
As a result, the collection of milestones will be received
For each milestone store:
Name
Description
Date
Archived flag
Archived Date
Collection of triggers

As a result, we will get the following structure of the data that should be stored in memory on the disk
Package Columns Collection
Package Column id
Packages collection
Package Id
Name
Archived
Start Date
Release Date
Description
Versions Collection
Version ID
Tags Collection
Tag
Comments Collection
Comment text
Milestones Collection
Milestone
Name
Description
Date
Archived flag
Archived Date
Collection of triggers
Trigger Id
Iterate all versions
For this step, we will be using a response to the GET Board request from Step 1.
In the same way, as for packages, the version collection is grouped by column ID. In each group, we have versions that belong to a particular column
We should process versions with the type “JIRA_VERSION”, other version types (basically virtual versions) could be skipped
We don’t need to store all the same as for the package as the version details should be already migrated to the cloud instance.
We need to only store mapping between the version ID and Column Id

As a result, we will get a collection column_Id1 -> {version_id1,version_id2,..... }; column_Id2 -> {version_id1,version_id2,..... }
Enrich Version with Tags from the same response extract tags from Collection: Tags-> versions. Actually in the same way as packages

In order to get comments, for each Version ID, execute the request:
GET https://<your_jira_url>/rest/release-management/1.0/board/<baord_id>/version/<version_id>/comment?versionType=JIRA_VERSION
Get the response and store comment values for each version. All other fields are not needed:

In order to get Milestones, for each Version ID, execute the request:
GET https://<your_jira_url>/rest/release-management/1.0/board/<board_id>/version/<version_id>/milestone
As a result, the collection of milestones will be received
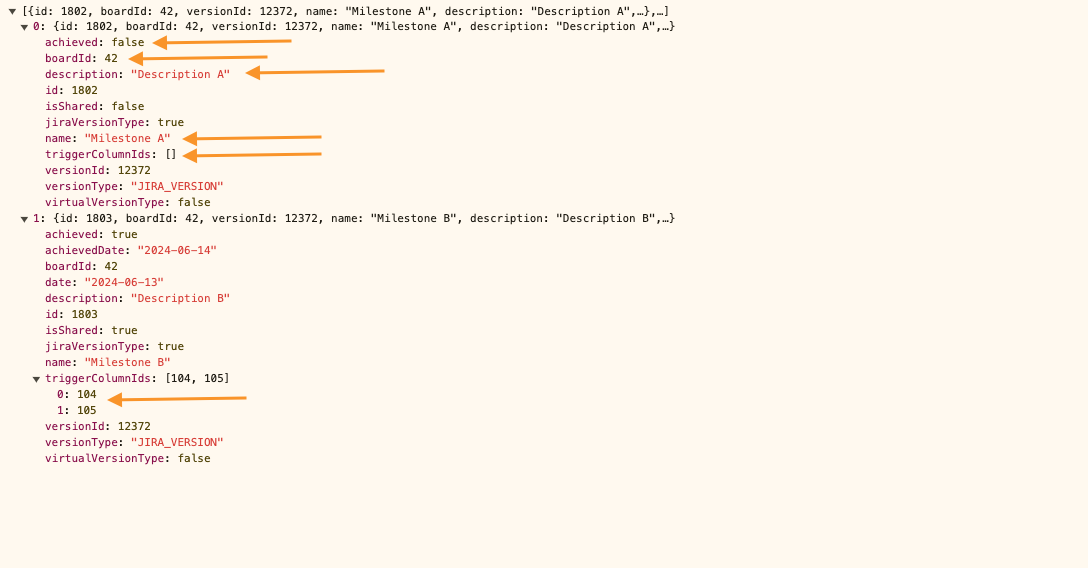
For each milestone store:
Name
isShared flag - it could be skipped as shared milestones are not available in the Cloud
Description
Date
Archived flag
Archived Date
Collection of triggers
As a result, we will get the following structure of the data that should be stored in memory on the disk
Version Column collection
Version Column Id
Versions Collection
Version Id
Tags Collection
Tag
Comments collection
Comment text
Milestones collection
Milestone
Name
Description
Date
Archived flag
Archived Date
Collection of triggers
Trigger Id
Data set structure after export is done
Main Data Set
Boards Collection
Board Id
Package Columns Collection
Package Column id
Packages collection
Package Id
Name
Archived
Start Date
Release Date
Description
Versions Collection
Version ID
Tags Collection
Tag
Comments Collection
Comment text
Milestones Collection
Milestone
Name
Description
Date
Archived flag
Archived Date
Collection of triggers
Trigger Id
Version Column collection
Version Column Id
Versions Collection
Version Id
Tags Collection
Tag
Comments collection
Comment text
Milestones collection
Milestone
Name
Description
Date
Archived flag
Archived Date
Collection of triggers
Trigger Id
Lookup Tables
Project ID
DC ProjectId -> Cloud Project ID
Version ID
DC Version ID ->Cloud Version ID
Board ID
DC Board ID -> Cloud Board ID
Package Column Mapping
DC Board ID, DC Package Column ID, Cloud Package Column ID
Version Column Mapping
DC Board ID, DC Version Column ID, Cloud Version Column ID
Step 5. Cloud Data Writing
These steps are to be executed for each board.
Before starting this step, please make sure that:
The boards are created in the cloud
All Columns are created for packages and versions
Locate board
From the Board IDs lookup table find a Cloud Board ID
Write packages
Create packages
Please use all entitled IDs from look-up tables to match DC IDs with Cloud IDs (for instance mapping of Cloumn ID)
For each package in the data set execute:
POST https://rmcloud-prd.releasemanagement.app/api/1/package
Payload:
{
"boardId":"<board_id>",
"name":"<Name>",
"description":"Migrated package Description",
"versionIds":[
"<version_id_from_lookup>",
"<version_id_from_lookup>",
"<version_id_from_lookup>"
],
"virtualVersionIds":[
],
"columnId":"<column_id_from_look_up>",
"synchronize":false,
"synchronizeParams":{
"name":true,
"description":true,
"startDate":true,
"releaseDate":true
},
"startDate":"<start_date>",
"releaseDate":"<end_date>"
}

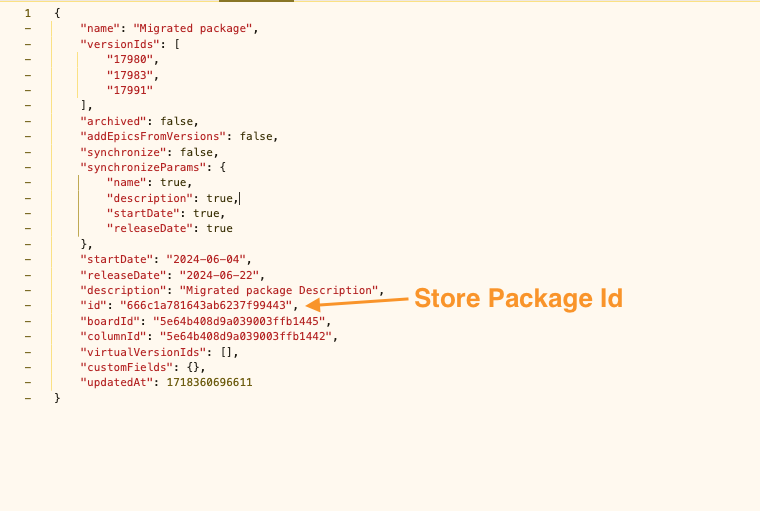
In response, the payload with the Package will be received, please store the package id, it will be used for the creation of tags, comments and milestones
Enrich with Tags
Tags could be taken as strings from the data set
For newly created packages execute the request:
POST https://rmcloud-prd.releasemanagement.app/api/1/tag/package/<package_id>
Payload:
["<add_tag_coma_separated>","<add_tag_coma_separated>"]

Enrich with comments
For each comment in the dataset execute the request:
POST https://rmcloud-prd.releasemanagement.app/api/1/package/<package_id>/comment
Payload:
{"content":"<comment text>"}
Enrich with milestones
For each milestone in the dataset please execute the requests
Create Milestone:
POST https://rmcloud-prd.releasemanagement.app/api/1/package/<package_id>/milestone
Payload:
{
"boardId":"<baored_id>",
"name":"<Milestone_name>",
"date":"<milestone_name>",
"packageId":"<package_id>"
}
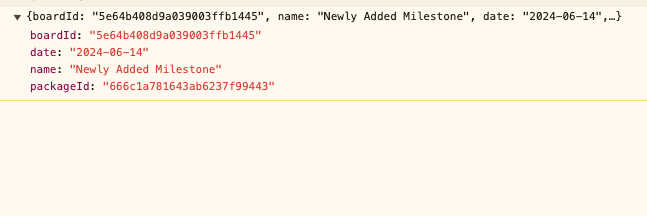
In the response, please take the newly created milestone ID
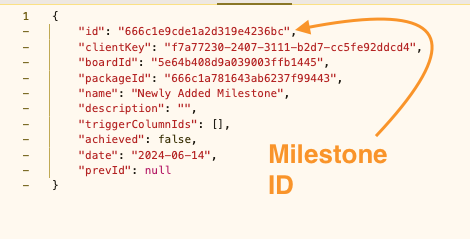
Update milestone with extra data
Execute request:
PUT https://rmcloud-prd.releasemanagement.app/api/1/package/milestone/<milestone_id>
Payloads:
Update description:
{"description":"new description"}
Update achieved flag:
{"achieved":true}
Update Achieved date:
{"achievedDate":"2024-06-11T21:00:00.000Z"}
Update Trigger by columns (use columns from lookup table )
{"triggerColumnIds":["5e64b408d9a039003ffb1442","5e64b408d9a039003ffb1441"]}
Multiple properties could be changed in a single request.
Extend versions data
Map versions to columns
For each version, please execute the request (NOTE: Please mind transition restrictions. Also, all IDs will be taken from look-up tables).
PUT https://rmcloud-prd.releasemanagement.app/api/1/board/<baord_id>/version/<version_id>/move?columnId=<colum_id>
Payload:
{"versions":[["<version_id>",true]]}
Enrich with Tags
Tags could be taken as strings from the data set
For newly created packages execute the request:
POST https://rmcloud-prd.releasemanagement.app/api/1/tag/version/<version_id>?type=0
Payload:
["<add_tag_coma_separated>","<add_tag_coma_separated>"]
Enrich with comments
For each comment in the dataset execute the request:
POST https://rmcloud-prd.releasemanagement.app/api/1/board/<baord_id>/version/<version_id>/comment
Payload:
{"content":"<comment text>"}
Enrich with milestones
For each milestone in the dataset please execute the requests
Create Milestone:
POST https://rmcloud-prd.releasemanagement.app/api/1/version/<vesion_id>/milestone
Payload:
{
"boardId":"<board_id>",
"name":"<name>",
"date":"<milestone_date>",
"versionType":0
}

In the response, please take the newly created milestone ID

Update milestone with extra data
Execute request:
PUT https://rmcloud-prd.releasemanagement.app/api/1/version/milestone/<milestone_id>
Payloads:
Update description:
{"description":"new description"}
Update achieved flag:
{"achieved":true}
Update Achived date:
{"achievedDate":"2024-06-11T21:00:00.000Z"}
Update Trigger by columns (use columns from lookup table )
{"triggerColumnIds":["5e64b408d9a039003ffb1442","5e64b408d9a039003ffb1441"]}
Multiple properties could be changed in a single request.